AI can produce software faster than most teams can review it.
That speed is useful, but it changes the bottleneck. The hard part is no longer only writing code. It is understanding what was produced, why it was produced, where it can run, and whether the resulting system can be reviewed with confidence.
For engineering teams, this creates a new requirement: AI-generated software must become reviewable by design.
BRIK64 is trust infrastructure for AI-generated and human-written software. Its purpose is not to replace engineering judgment, security review, or formal verification. Its purpose is to make software structure easier to inspect, constrain, certify, and compile across targets.
In short: make software reviewable again.
The review problem with generated code
AI coding tools can produce large amounts of implementation detail from a small amount of intent. That creates leverage, but it also creates opacity.
A reviewer may receive a working branch, a generated component, or a full application scaffold. The code may pass basic checks. It may even appear idiomatic. But important questions remain:
- What was the intended architecture?
- Which assumptions are embedded in the generated implementation?
- Which interfaces are stable and which are incidental?
- Which parts are safe to regenerate?
- Which deployment targets are supported?
- What evidence exists that the structure matches the intent?
Traditional code review was built around human-authored diffs. AI-generated software can turn that model inside out: instead of reviewing a small change, teams may need to review a generated structure whose rationale is not explicit in the code itself.
When the source of truth is only the generated output, reviewers are forced to reverse-engineer intent from implementation.
That is fragile.
Reviewability starts before code
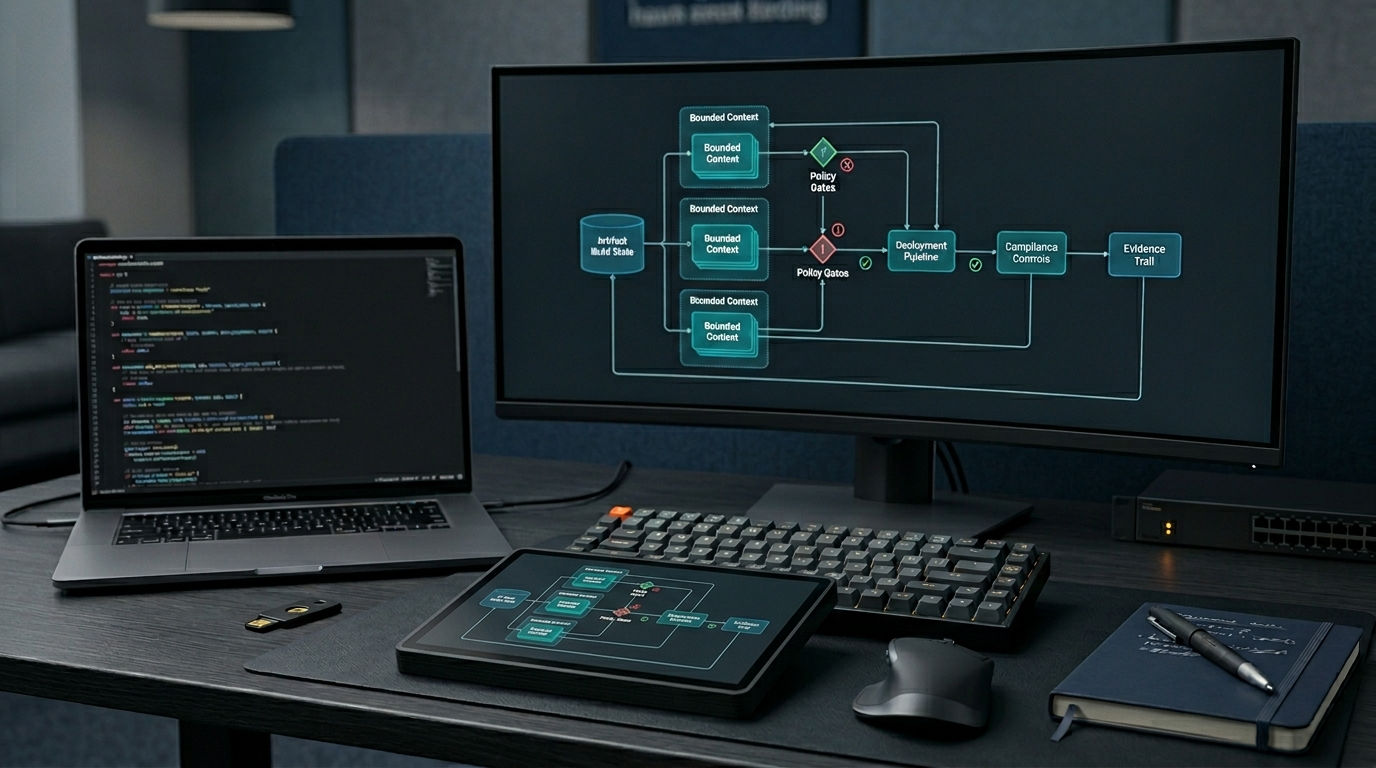
Reviewable software needs more than readable code. It needs a reviewable blueprint.
A blueprint captures the structural decisions that should remain visible before, during, and after code generation. It gives teams a place to inspect the shape of the system before implementation details take over.
For AI-assisted development, this distinction matters. Generated code can be useful, but code alone is a poor container for intent. A blueprint gives reviewers a higher-level artifact to inspect:
- system boundaries
- component responsibilities
- data flow
- interfaces
- target environments
- constraints
- invariants
- generation assumptions
This does not eliminate source review. It makes source review less blind.
Instead of asking only whether the generated code works, teams can ask whether the generated code reflects an inspectable structure.
From prompt output to governed structure
A prompt is not a governance model.
Prompts are useful for expressing intent, but they are not enough to establish durable engineering control. They are often informal, incomplete, and hard to audit. The same prompt can produce different outputs depending on model behavior, context, tools, and surrounding code.
A reviewable system needs artifacts that are more stable than a prompt transcript.
BRIK64’s framing is mechanism-first:
Inspect the blueprint. Certify the structure. Compile across targets.
This separates three concerns that are often collapsed in AI-generated software workflows.
First, the blueprint should be inspectable. Teams need a representation of the system that can be reviewed before implementation becomes the only artifact.
Second, the structure should be certifiable within stated boundaries. Certification here means creating bounded, reviewable evidence about structural conformance. It should not be confused with a broad legal, regulatory, or security guarantee.
Third, implementation should be generated or compiled across targets from a structure that remains visible. This helps teams reason about what changed when moving across environments, frameworks, or deployment surfaces.
Human review still matters
Reviewable AI-generated software is not software that no longer needs humans.
It is software that gives humans better things to review.
A reviewer should not have to infer the entire system model from generated files. They should be able to inspect the declared structure, compare it with generated artifacts, and identify where judgment is required.
This supports a clearer division of labor:
- AI can help produce implementation detail.
- Structural artifacts can preserve intent and boundaries.
- Reviewers can inspect architecture, constraints, risk, and exceptions.
- Build and generation systems can produce target-specific outputs.
The goal is not blind automation. The goal is accountable acceleration.
What reviewable generation requires
Making AI-generated software reviewable requires discipline in several areas.
1. Explicit structure
The system needs a visible structure that exists outside the generated code. This structure should describe components, responsibilities, interfaces, and boundaries in a form reviewers can inspect.
2. Bounded claims
AI-generated systems should avoid broad claims such as “secure,” “compliant,” or “verified” unless those claims are backed by specific evidence and clearly stated scope.
A better claim is bounded: this structure conforms to these declared constraints under these assumptions.
3. Traceable outputs
Generated artifacts should be traceable back to the blueprint or structural source. When code changes, teams should be able to reason about whether the blueprint changed, the compiler changed, or the generated output changed manually.
4. Target awareness
Software rarely lives in one environment forever. A reviewable system should make target assumptions explicit: runtime, framework, platform, integration boundaries, and deployment model.
5. Review checkpoints
The workflow should create moments where humans can inspect and approve structure before implementation expands. Review checkpoints reduce the risk that teams accept a large generated codebase without understanding the underlying design.
Why this matters for enterprise teams
Enterprise software teams do not only need faster code. They need systems they can maintain, audit, adapt, and explain.
AI-generated software increases the need for structural clarity because it can increase the distance between intent and implementation. When that distance is unmanaged, teams may ship code they can run but cannot confidently review.
BRIK64 is built around the opposite idea: the structure should remain visible.
That visibility supports better engineering conversations. Architects can inspect system shape. Reviewers can evaluate boundaries. Platform teams can reason about targets. Security and governance stakeholders can ask sharper questions about assumptions and evidence.
This does not make risk disappear. It makes risk easier to locate.
Make software reviewable again
AI changes how software is produced, but it should not remove the need for engineering accountability.
The next generation of software tooling should not treat generated code as the only artifact that matters. It should preserve the blueprint, expose the structure, and keep review boundaries visible.
That is the role BRIK64 is designed to play.
BRIK64 helps teams move from generated output toward reviewable software structure: inspect the blueprint, certify the structure, and compile across targets.
Make software reviewable again.