AI coding tools have changed how software is produced. A developer can describe intent in natural language, receive working code, ask for revisions, and move quickly from idea to implementation.
That speed is useful. It is also incomplete.
A prompt is not evidence. Generated code is not automatically reviewable. Passing tests do not necessarily explain the structure of what was built. For teams working in regulated, safety-sensitive, enterprise, or long-lived systems, the central question is not only whether AI can generate code. The question is whether the resulting software can be inspected, reviewed, maintained, and compiled within clear technical boundaries.
BRIK64 is designed around that boundary.
It treats reviewability as infrastructure. The goal is not to replace human engineers, security review, compliance work, or formal assurance. The goal is to make the software structure visible enough that those processes have something more precise to inspect.
The problem with prompt-to-code workflows
A typical AI coding workflow has a narrow visible trail:
1. A human writes a prompt.
2. An AI system generates or edits code.
3. The developer runs tests or manual checks.
4. The code is merged, deployed, or handed to another team.
This workflow can be fast, but it leaves important questions open.
What structure did the AI actually produce? Which assumptions are now embedded in the implementation? Which parts of the result are essential logic, and which parts are incidental glue? Can another engineer review the system without reverse-engineering every line? Can the same structure be compiled or emitted across different targets without changing the intended computation?
In many teams, the review artifact remains the source code itself. That is sometimes enough. But in AI-assisted development, source code can be verbose, inconsistent, overfitted to local context, or shaped by hidden model behavior. Reviewers may spend time interpreting incidental implementation details instead of inspecting the underlying computational structure.
The result is a gap between generation and assurance.
Why the blueprint matters
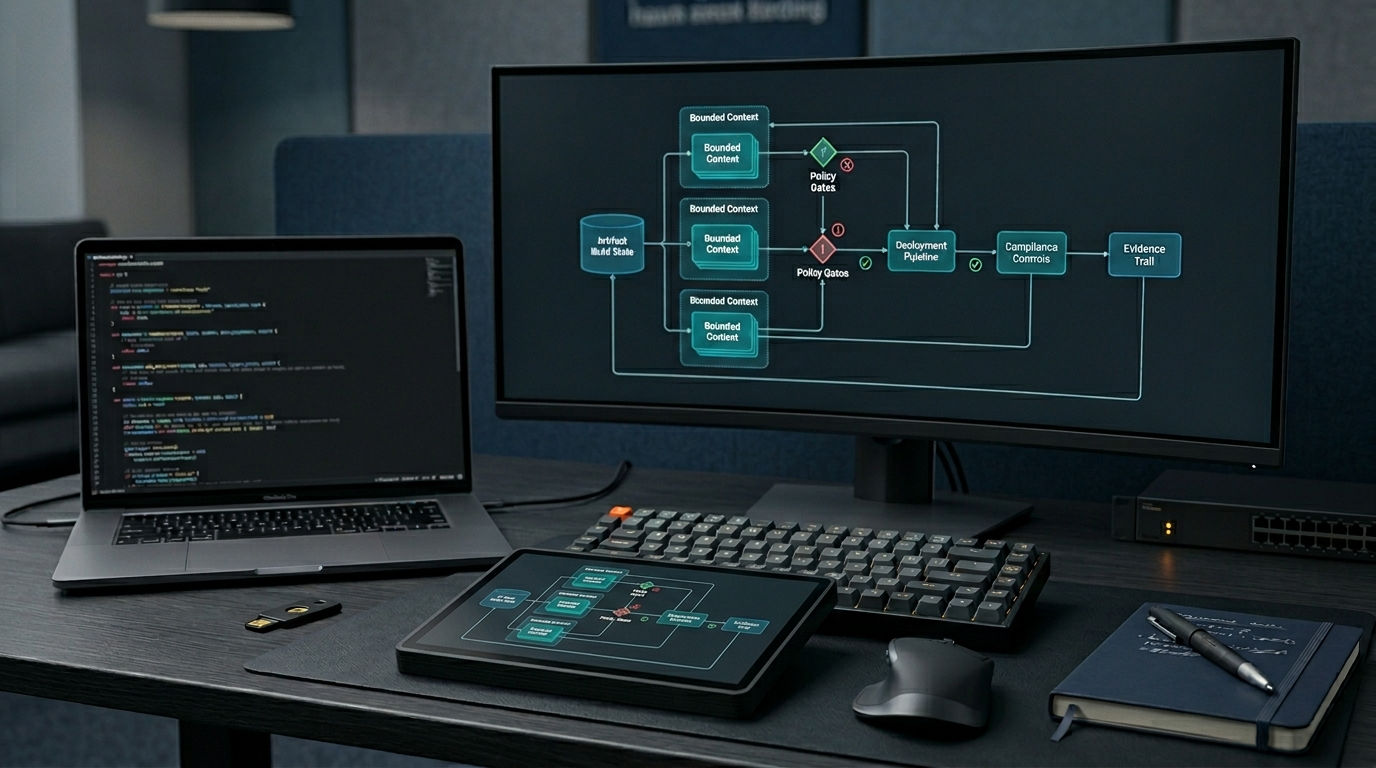
BRIK64’s approach is to introduce a structural intermediate layer: the blueprint.
A blueprint is not a marketing diagram. It is a bounded representation of the software structure that can be inspected before target-specific output is produced. In BRIK64 terms, this is where computational form, dependencies, interfaces, and intended structure become explicit enough to support review.
This changes the workflow from:
prompt → generated code → tests → merge
to something closer to:
prompt → generated code or lifted source → blueprint → review → target compilation
That intermediate step matters because it gives teams a place to ask better questions.
Is the structure coherent? Are the boundaries clear? Are the intended components visible? Does the blueprint expose the parts of the system that should be reviewed before output code is trusted? Can the same reviewed structure be compiled into different targets under controlled assumptions?
The blueprint does not prove that all software behavior is safe. It does not remove the need for human review. It does not replace formal verification. But it can improve the review surface by separating the structure of the program from the incidental form of one generated output.
AI-generated code needs external structure
AI coding systems are powerful, but their outputs are shaped by probability, context, examples, and local instructions. They may generate useful code, but they do not automatically create a durable review trail.
For small scripts, that may be acceptable. For larger systems, it creates operational risk.
Teams need to know what changed, why it changed, and whether the resulting structure still matches the intended design. They also need a way to review software that may have been produced by several model calls, across multiple sessions, by different developers or agents.
A blueprint-oriented pipeline gives teams a more stable checkpoint. Instead of treating the generated source file as the only artifact, the workflow extracts or constructs a reviewable representation that can be examined before compilation or integration.
This is especially useful when AI is used for:
- generating service logic,
- refactoring existing code,
- translating between languages,
- modernizing legacy systems,
- producing SDKs or integration layers,
- creating repetitive implementation scaffolding.
In each case, the question is not whether AI can produce text that looks like code. It often can. The question is whether the resulting software can be made structurally reviewable.
Human review becomes more focused
Human review is still essential. The point of a blueprint is not to remove reviewers from the process. It is to give them a better object to review.
When reviewers inspect only generated code, they may have to infer architecture from implementation. When they inspect a blueprint, they can focus on structure first:
Are the components correctly separated? Are the inputs and outputs clear? Are the computational boundaries visible? Does the structure match the intended design? Are there unexpected dependencies or transformations?
After that, reviewers can inspect emitted code, tests, runtime behavior, and deployment configuration with more context.
This sequencing is important. It helps prevent review from becoming a line-by-line attempt to reconstruct intent after the fact. Instead, teams can inspect the structure before it becomes target-specific output.
Compilation across targets
One of the strongest reasons to use a blueprint layer is target separation.
In many systems, the same intended logic may need to appear in different environments: backend services, SDKs, edge functions, integration code, test harnesses, or migration targets. Without a structural intermediate representation, each target can become a separate implementation to review.
BRIK64’s positioning is different: inspect the blueprint, certify the structure within stated boundaries, and compile across targets.
This does not mean every target is automatically equivalent in all runtime conditions. Target environments still have different libraries, constraints, security models, and operational behavior. But it does mean teams can reduce unnecessary divergence by reviewing a shared structural artifact before target-specific compilation.
That makes the review process more disciplined.
A practical pipeline for AI-assisted teams
A reviewable AI coding pipeline can be organized around five checkpoints.
First, capture intent. The prompt, task description, issue, or specification should define what the system is supposed to do, but it should not be treated as evidence that the result is correct.
Second, generate or lift implementation. AI may generate new code, modify existing code, or help translate legacy systems. Existing code may also be lifted into a structural representation.
Third, inspect the blueprint. This is where the software structure becomes the primary review object. Reviewers can examine computational form, boundaries, dependencies, and target assumptions.
Fourth, compile or emit target code. Once the blueprint is reviewed within its intended scope, target-specific outputs can be produced.
Fifth, validate in context. Tests, security review, compliance review, runtime checks, and human approval remain necessary. The blueprint improves reviewability; it does not eliminate downstream assurance.
This pipeline is intentionally bounded. It avoids the unsafe claim that AI-generated software can be trusted because it was generated by a model, passed a test suite, or came from a preferred tool. Instead, it creates an explicit review layer between generation and deployment.
What this changes for engineering organizations
For engineering leaders, the value is governance without pretending that governance is magic.
A reviewable pipeline can help teams document what was generated, what structure was reviewed, what target outputs were produced, and where human judgment was applied. That can make AI-assisted development easier to manage across teams.
For developers, the value is clarity. The blueprint gives them a structural artifact that is less noisy than raw generated code and more concrete than a prompt.
For reviewers, the value is focus. They can inspect architecture and computational shape before becoming trapped in implementation details.
For platform teams, the value is consistency. A shared blueprint layer can support repeatable workflows across projects and targets.
None of this turns AI output into review-scoped software by default. It simply makes the path from AI-assisted generation to reviewable software more explicit.
Make software reviewable again
The next phase of AI coding will not be won by speed alone. Fast generation is useful, but software organizations also need durable review surfaces, bounded compilation, and clear evidence trails.
BRIK64’s thesis is that reviewability must become part of the infrastructure.
A prompt can start the process. Generated code can accelerate implementation. But the blueprint is where teams can inspect the structure before they trust the output.
That is the difference between producing more code and producing software that can be reviewed.
Make software reviewable again.